Re‑Typograph 2013
Thomas Bouville zoomThinking a generative tool able to create a typeface from a printed book. In collaboration with Loria (Laboratoire lorrain de recherche en informatique et ses applications), Nancy.
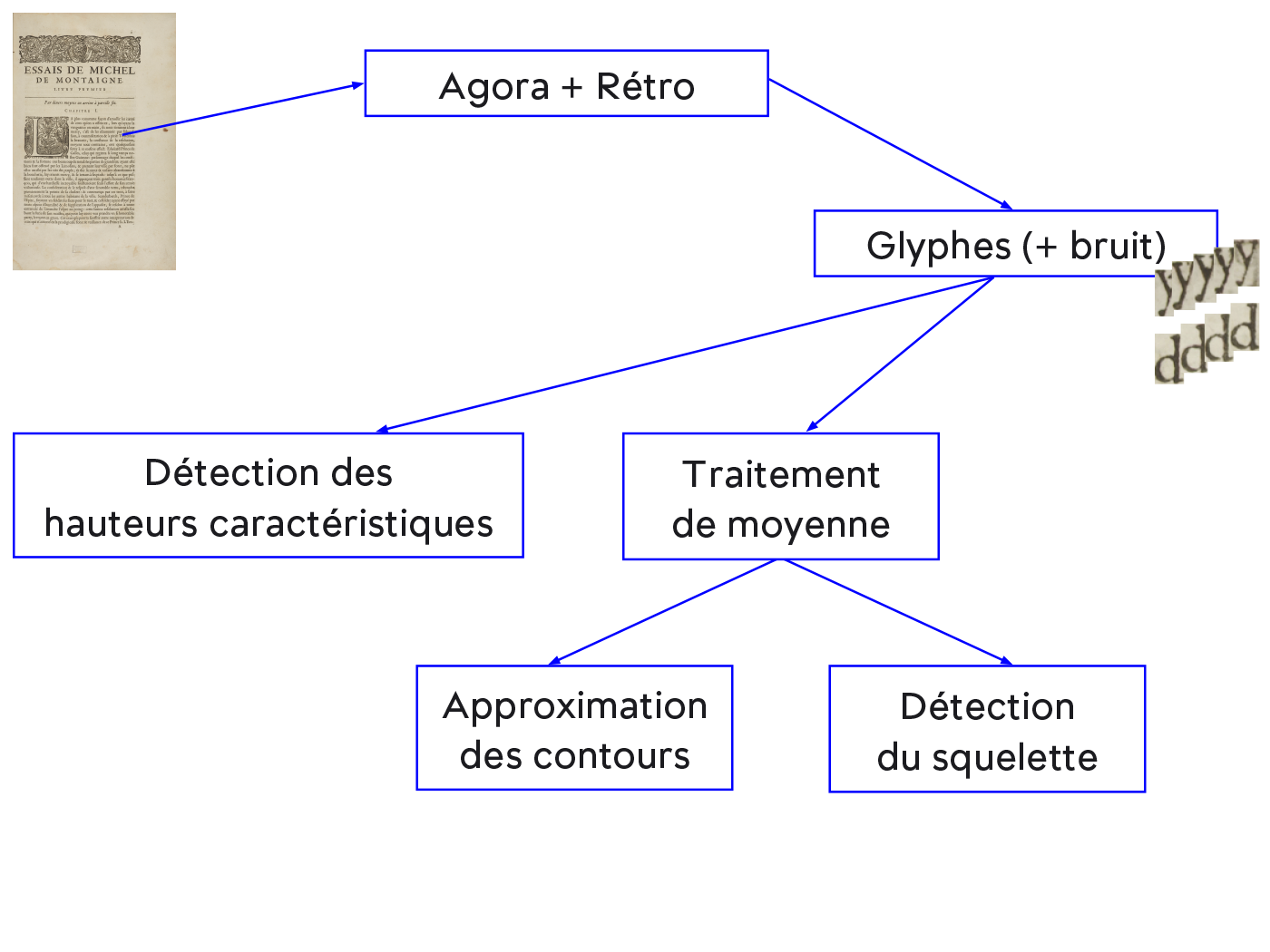
Re‑typograph project was initiated in 2013 at the initiative of a partnership between the ANRT and the Loria (Lorraine Research Laboratory in Computer Science and its Applications). It takes its basis on results given by softwares developed at the CESR Tours for the study of old books from the Renaissance period. The project aims in long-term to rebuild old printed books in completely digital and dynamic versions. This approach provides the possibility to rethink the current possibilities for displaying documents online. Looking at palaeographer Marc Smith’s research on the different levels of transcriptions, Re‑typograph project aims to reproduce the so-called “conservative” state : an OCR able to preserve the typographic form of the original document. The aim of such a program is to obtain a faithful digital copy close to the facsimile, freed from printing errors, with fully encoded and dynamic text. It should also result in smaller file sizes compared to regular images, which should facilitate data exchange. The project was based initially on the Retro and Agora software developed at CESR in Tours, which gave the possibility to extract letters as images from scanned books. Based on the observation that all instances of a letterform within a document are almost identical, the first part of the project consisted in generating average forms based on images of letters extracted Renaissance documents. Thereafter, different ways of describing letterforms digitally were tested.
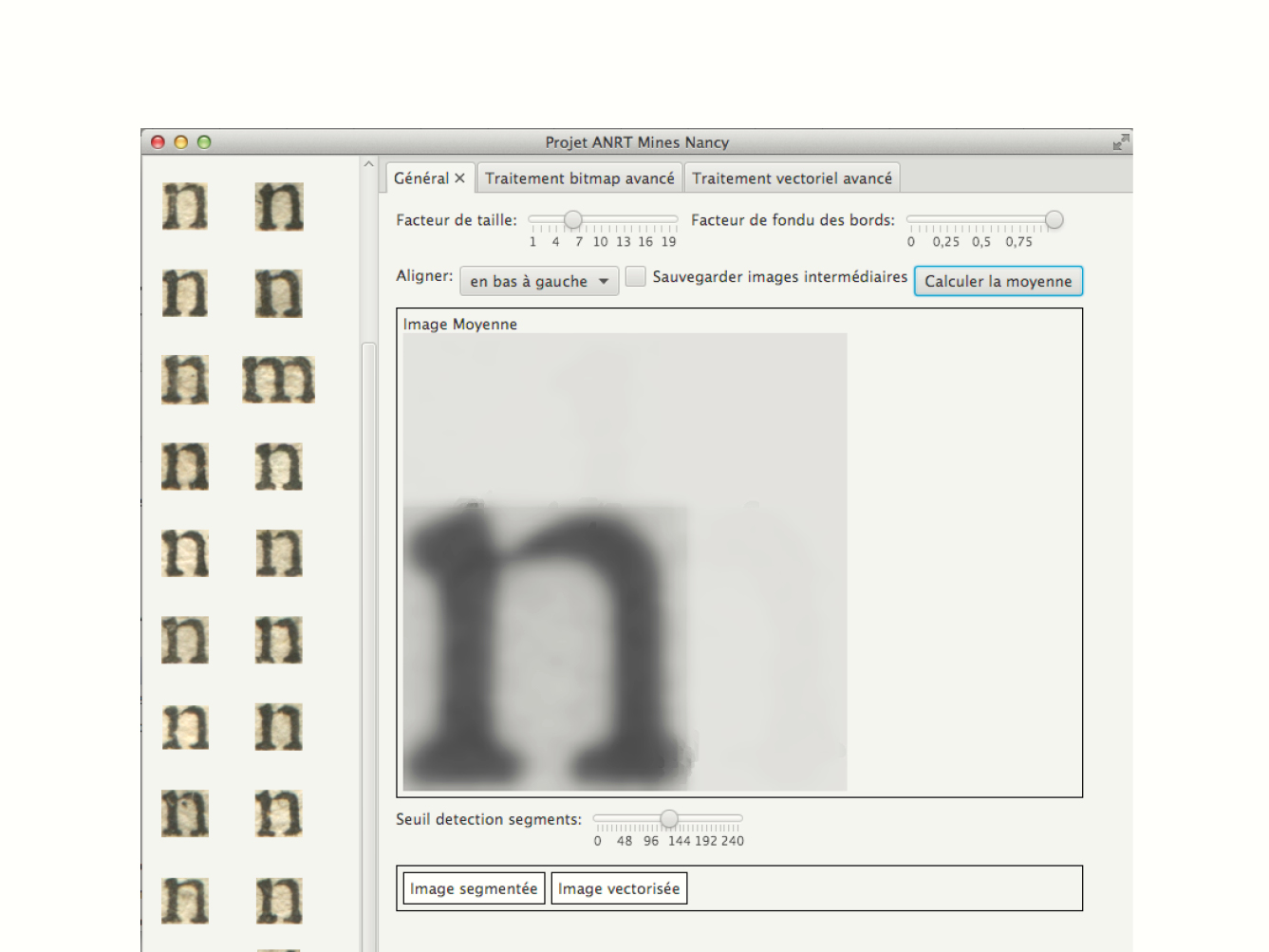
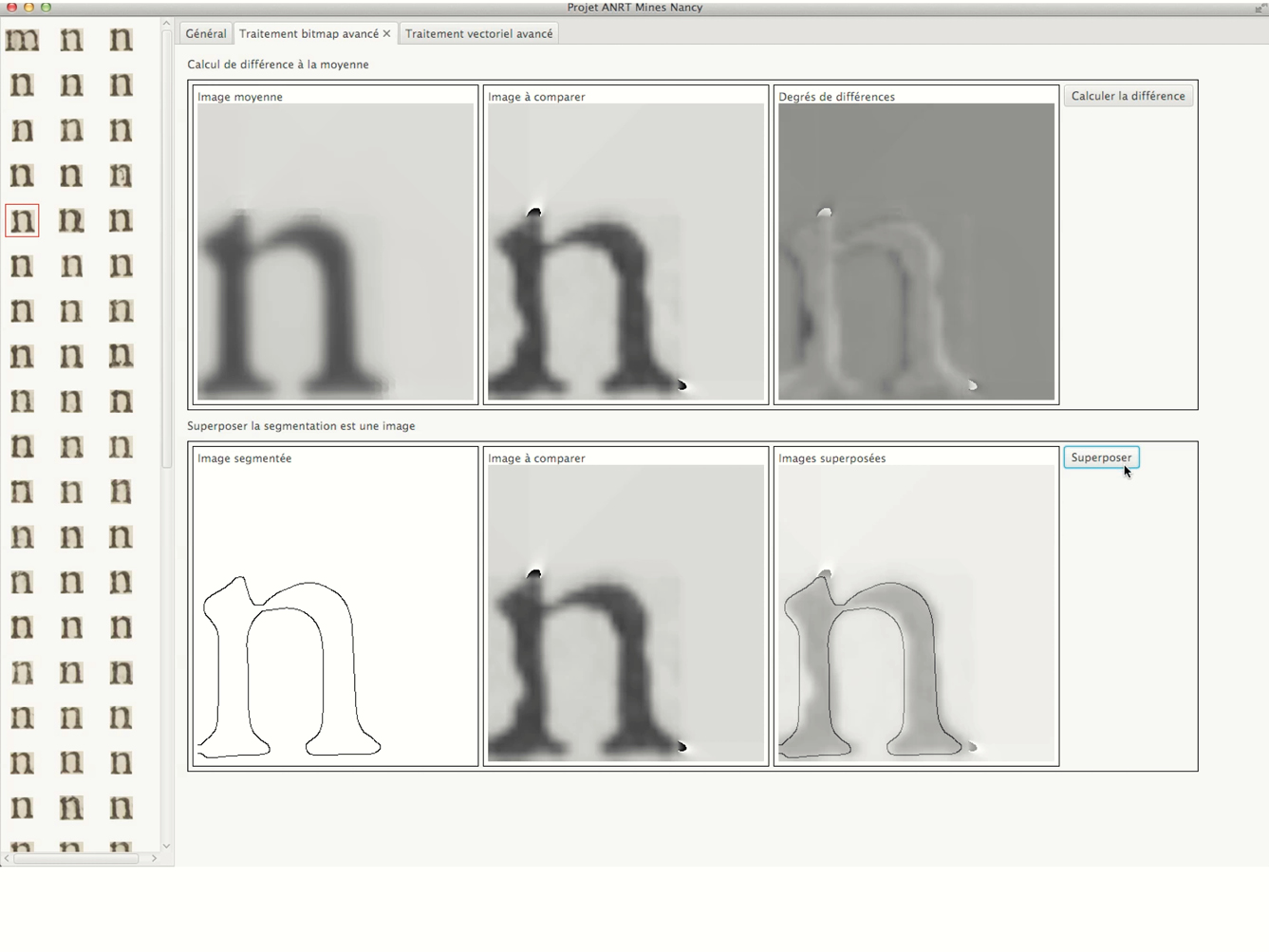
Two groups of students in computer sciences collaborated. Their work enabled us to research existing algorithms for image analysis, to design interfaces and to understand the limits of the tools at our disposal. Students of Mines Nancy developed an average treatment method focused on greyscale images analysis, from which they generated raster outlines as well as vector approximation. The average letter could also be compared to any occurrence in order to refine the settings. Télécom Nancy students chose another approach to compute the average form. They then developed skeleton detection algorithms, from which they tried to segment and describe the letters. The program had to find connections in the glyph, to segment it, to deduce if the segment was a line or a curve, and to define where thick and thin were placed.
After one year of research, these different approaches opened up great hopes for the digital reconstitution of ancient documents. The last trials were focused more on baseline detection. This marked the beginning of parameter extraction from a scanned source, with the objective of automating the font synthesis process.