Interfaces (trans)textuelles
Sylvain Julé zoomCette recherche engage un travail autour des formes sous lesquelles l’écrit se donne à lire sur nos supports numériques.
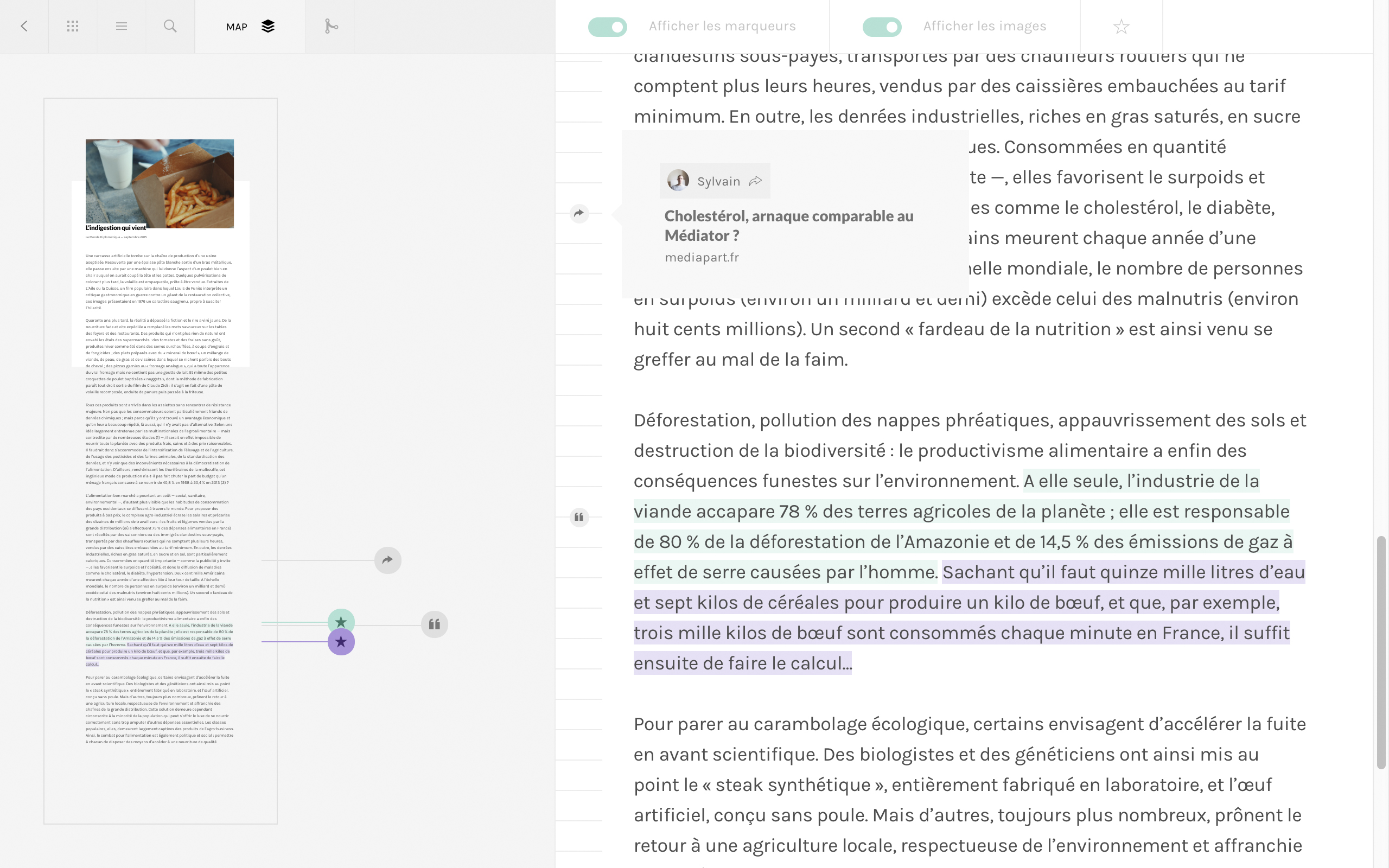
Texte linéaire et hypertexte ne sont pas seulement deux modes de textualité divergents, ce sont surtout deux outils radicalement différents de représentation de la mémoire. À la volonté de son externalisation et de sa cristallisation encyclopédique sous une forme figée, linéaire, analytique et objectivement distanciée telle que l’imprimerie a pu la formuler, l’hypertexte et l’écrit sur écran lui oppose une conception vivante, récursive et ouverte du savoir. Une des ambitions de cette recherche est, à travers le développement d’interfaces expérimentales, de préciser les enjeux formels et interactifs qui découlent de ce constat, à différentes échelles (de l’architecture globale de l’information aux spécificités de la perception du signe sur écran), délaissant ses pratiques de référence héritées de la page imprimée, et questionnant tout particulièrement l’influence de ces outils sur les processus cognitifs mis en jeu lors de la lecture.
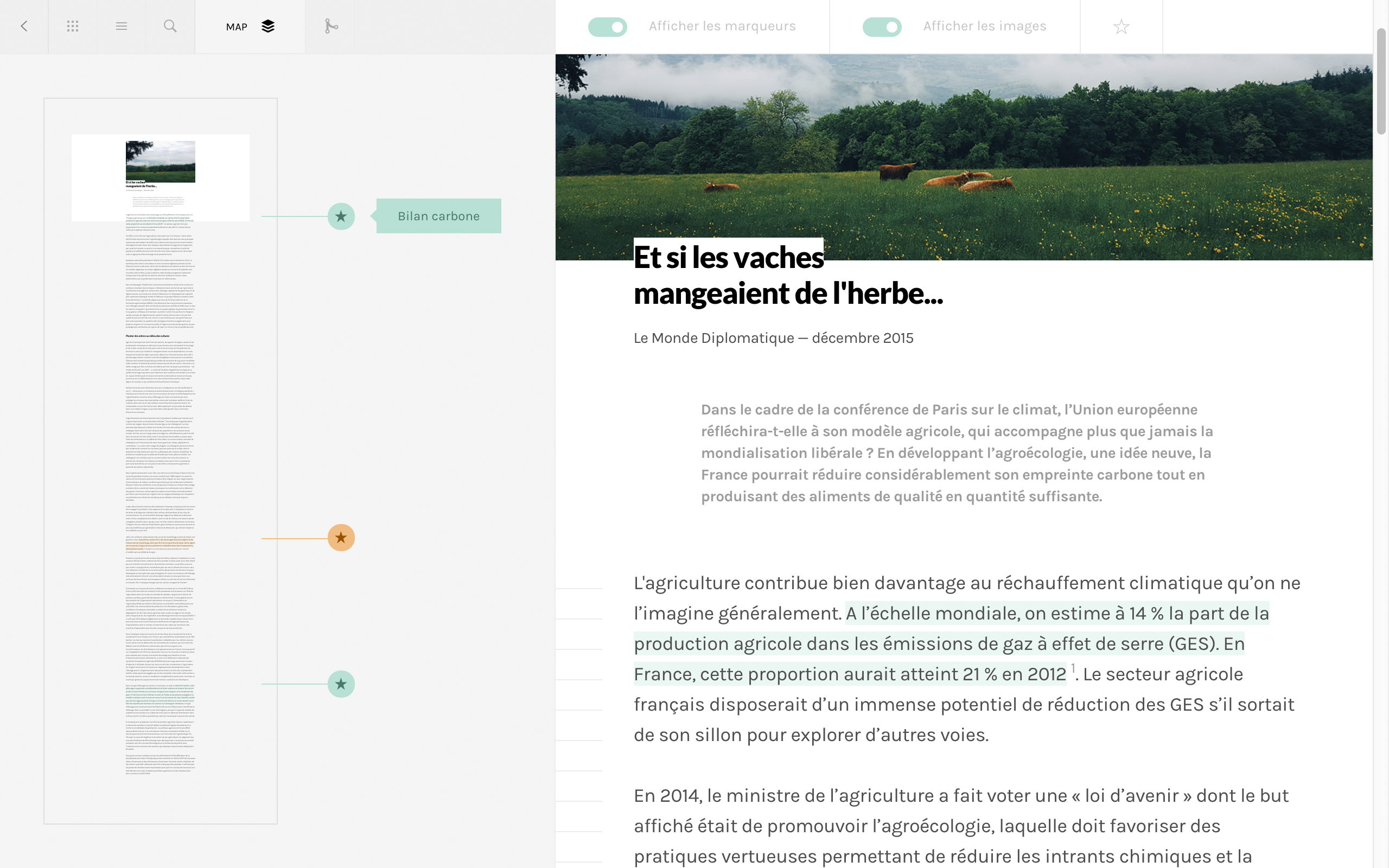
L’intérêt porté à la question de la lecture numérique réside dans son émancipation d’une pratique de lecture telle que formulée depuis l’apparition de l’écriture et précisée par les différents sollicitations du support papier, par essence figé, engageant ainsi une profonde restructuration cognitive. La question typographique y cohabite dès lors avec des problématiques connexes. Une première partie de ce projet a permis d’esquisser des interfaces interrogeant nos mécanismes perceptifs, utilisant un eye-tracker (permettant de détecter et suivre la position de l’œil sur l’écran) comme outil d’interaction. Ces questions ont ensuite été confrontée à celle d’une transtextualité telle que le collectif Tel quel, puis Gérard Genette, la formule. Une seconde partie a ainsi investi des corpus de documents complexes, en s’intéressant à la représentation des relations établies entre chacun, à différents échelles et selon différents niveaux de relations.
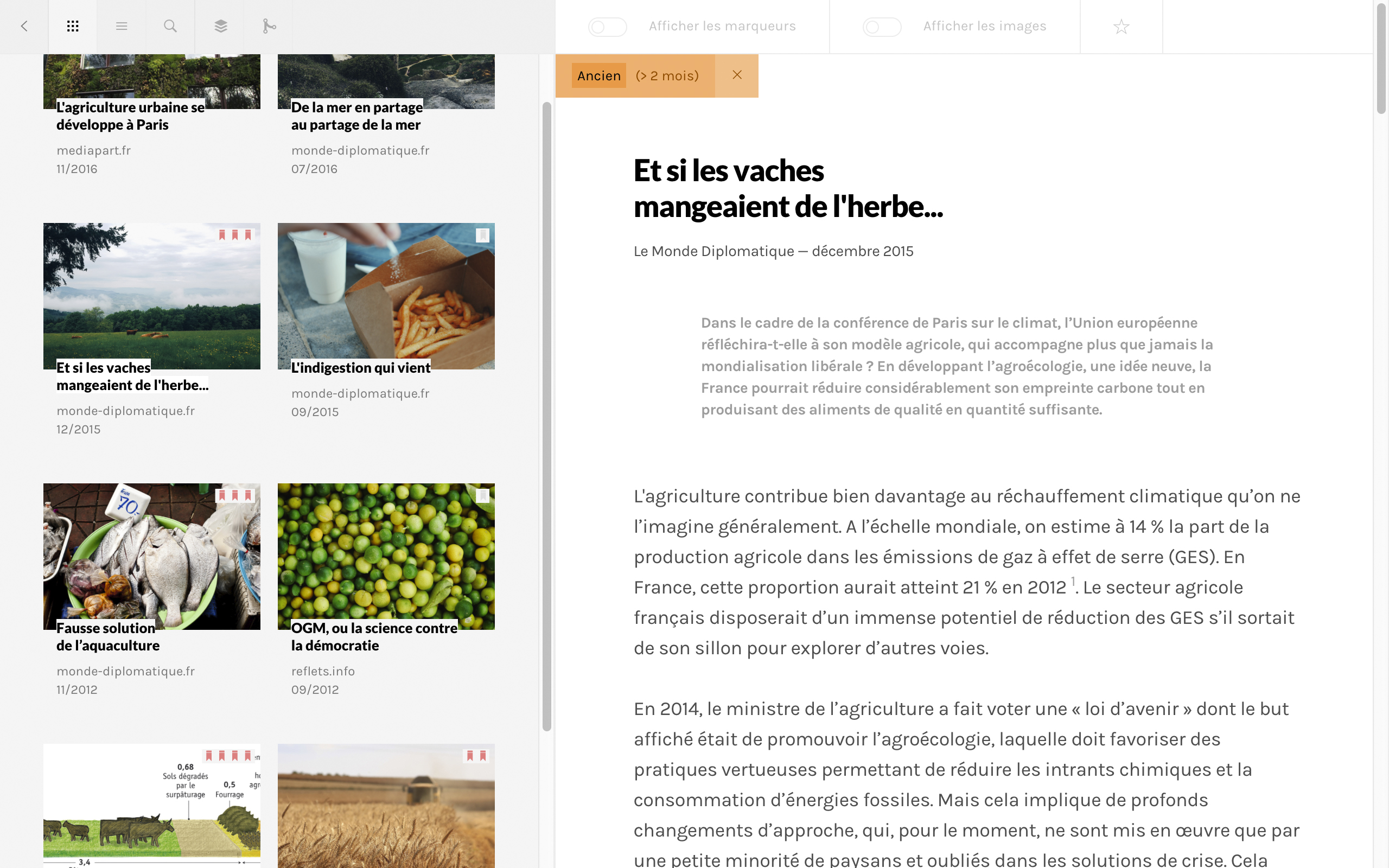
Les 6 derniers mois de ce projets ont été dédiés au développement des prémices d’un outil de collecte, lecture et balisage d’articles extraits de sites d’information.