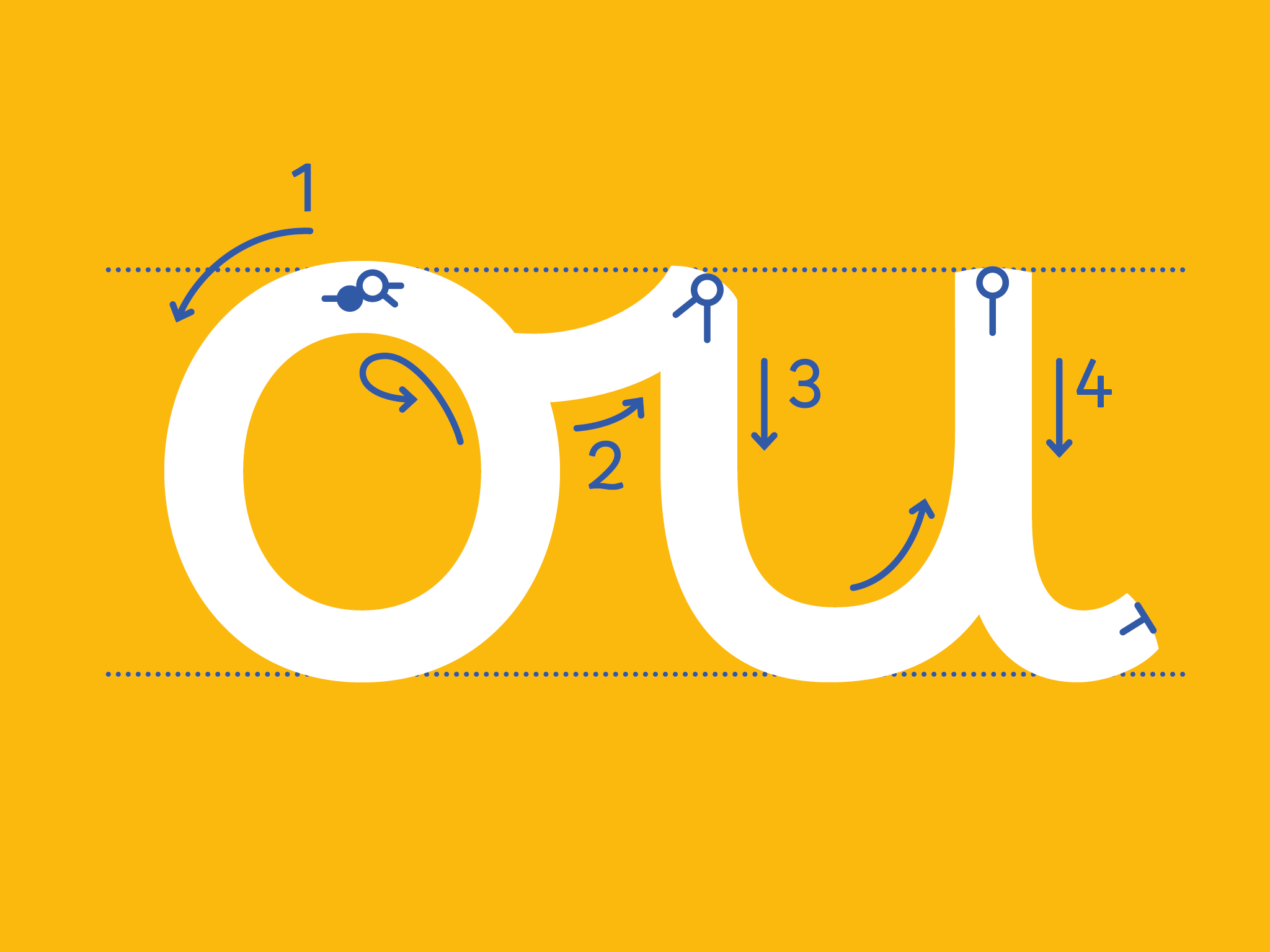The Missing Scripts Les écritures manquantes de l’Unicode
Le programme de recherche The Missing Scripts a été initié en 2016, en partenariat avec l’Université des sciences appliquées de Mayence (Allemagne) et le Department of Linguistics de l’Université de Berkeley (Californie).
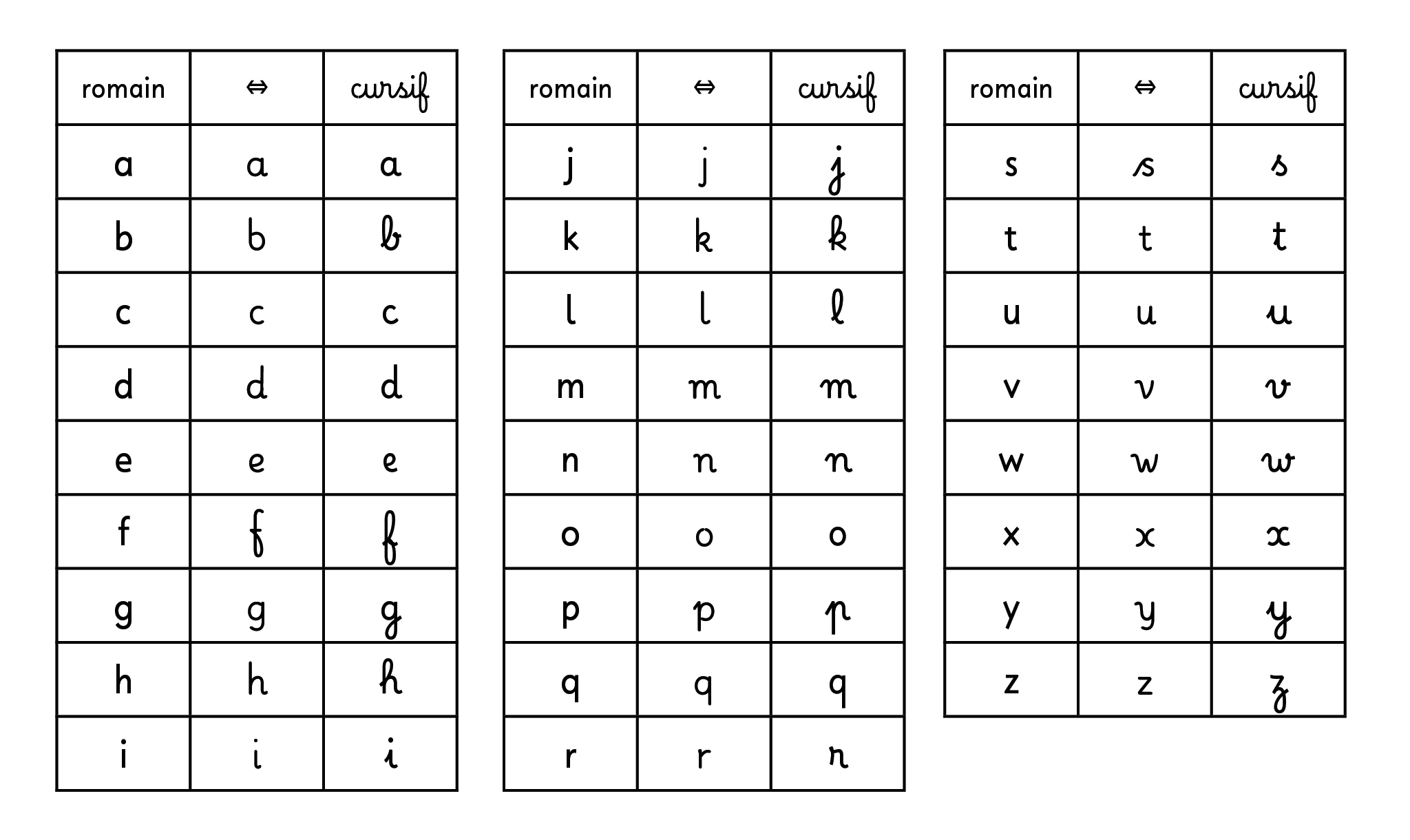
À l’origine, il y a le constat que la moitié des écritures du monde ne sont pas encodées dans le standard Unicode, et par conséquent ne sont pas accessibles sur ordinateur ou smartphone (146 sur 292 en 2016, 133 sur 292 à ce jour). Exclues de l’éco-système numérique, ces écritures (vivantes ou anciennes) sont menacées d’extinction.
Pour soutenir et préserver cette diversité, l’ANRT accompagne les travaux du Script Encoding Initiative (Berkeley UC) pour intégrer ces écritures disparues ou minoritaires au standard universel Unicode, et leur donner une forme typographique, souvent pour la première fois. Ces fontes, élaborées avec des experts et des scripteurs de chaque écriture, constituent souvent des défis techniques et scientifiques, et peuvent nécessiter plusieurs années de développement.
Johannes Bergerhausen, designer et professeur au designlabor Gutenberg de la Hochschule Mainz, a créé le poster et le site web The World’s Writing Systems à partir des glyphes dessinés à l’ANRT pour les Missing Scripts, et le Decode Blockdock dessiné par Jérôme Knebusch. Publié par l’ANRT, ce poster est mis à jour régulièrement: la 3e édition a été publiée en 2021.
Chaque année, des étudiant·e·s de l'ANRT développe des fontes numériques pour des écritures nouvellement encodées ou en passe de l'être. Ces travaux contribuent à préserver et à développer une expertise typographique pour ces écritures minoritaires, vivantes ou disparues.
Contenus associés
Colloque
Site web
Partenariats
Hochschule Mayence
Institut Designlabor Gutenberg, Mainz (DE)
Professeur associé: Johannes Bergerhausen
University of Berkeley
Berkeley, CA 94720-2650 (USA)
Dept. of Linguistics
Script Encoding Initiative
Professeur associé: Deborah Anderson